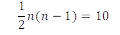Op 5 januari 2020 om 19:00 uur start de première over de trucs die je kan doen met SPSS over filters, selecties en randomisatie.
Er is tevens live chat!
Op 5 januari 2020 om 19:00 uur start de première over de trucs die je kan doen met SPSS over filters, selecties en randomisatie.
Er is tevens live chat!

Dus niet: kansen draaien óm bij verwachtingen.

Bedenk dat spreiding het centrale begrip in de statistiek is: alles draait om spreiding. Hoe het gespreid is, hoe de waarnemingen (of getallen, of gegevens) verdeeld zijn rondom een midden.
Op 16-12-2019 om 19:00 uur precies start de première van de SPSS-clip over data cleaning. Oftewel: maak je data schoon voordat je start met analyseren.
Er is live video chat!
Deze student legt het nog een keer uit aan een andere student: ‘het is toch logisch dat het tweede kwartiel kleiner is dan de interkwartielafstand’.

De interkwartielafstand is bepaald door de ‘grijze box’ in de figuur, dat is het verschil tussen Q3 en Q1 en is óók een maat voor de spreiding.
Het tweede kwartiel is kleiner dan de interkwartielafstand? Nee, die vlieger gaat niet altijd op. Stel Q1=4, Q2=5 en Q3=6 .
Dan is de interkwartielafstand: Q3 – Q1 = 6 – 4 = 2.
Dus nee, want Q2=5 en is groter dan 2. (QED)
Weifelend vraagt de student om bevestiging: ‘dus een histogram gebruik je alleen bij continue variabelen?’
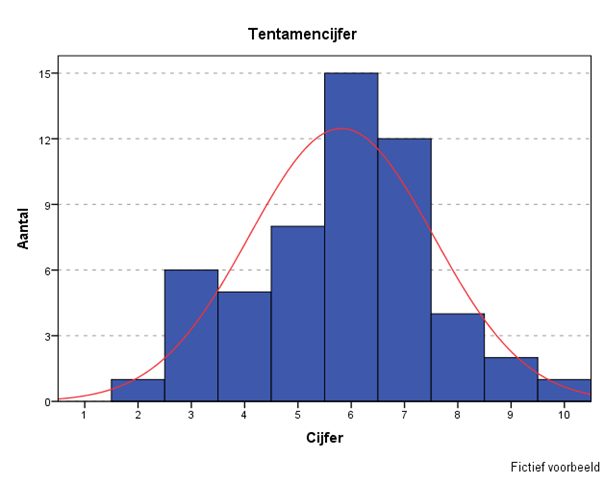
Ja!
Voor categorische variabelen, oftewel niet-continue variabelen, oftewel discrete variabelen gebruik je een (gewone) staafdiagram.
Wat is de definitie van chaos?

Een statisticus zonder het toetstheorema van Fisher:
Beter één verzameling in de hand, dan tien onbekend.


Vraag van een student
Ik maak gebruik van 5 verschillende overtuigingsprincipes van Cialdini en één controlegroep. Dan klopt het toch dat ik na mijn steekproefberekening, die uitkwam op een minimum van 385 respondenten, in totaal (dus 5 principes + controlegroep) minimaal 385 respondenten moet hebben?
Antwoord
Van belang voor het antwoord is of er wel of geen interactie-effecten zijn. Laat ik het voorbeeld vertalen naar een nog wat eenvoudiger voorbeeld. Stel dat je wil weten wat de mensen van de kwaliteit van het brood van de bakker vinden, specifiek van:
Opzet zonder interactie-effect
Dus je maakt een testopzet waarmee je een proefpanel organiseert die drie soorten brood gaan proeven. Je trekt een steekproef van X1 mensen voor bruin brood, X2 mensen voor wit brood en X3 mensen voor stokbrood. Voor de goede orde: het is trekking zonder teruglegging, dus een persoon kan maar in één van de groepen (1 = bruin brood, 2 = wit brood, 3 = stokbrood) zitten:
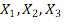
Stel dat je de kwaliteit met een rapportcijfer meet, dan krijg je dus drie gemiddelden:
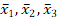
Dit zijn drie onafhankelijk getrokken steekproeven. De gemiddelden beïnvloeden elkaar niet. De steekproefberekening gaat dan per segment:
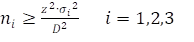
Stel verder dat het steekproefgemiddelde maar een kwart mag afwijken, dat je 95% betrouwbaarheid wil en dat de standaarddeviatie 1,0 bedraagt:
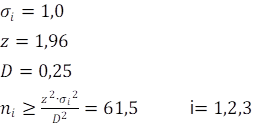
Dus de steekproef per segment is dan 62 personen. Totaal moet je dan 186 verschillende respondenten werven.
Opzet met interactie-effect
Als je nu de opzet wijzigt, zodanig dat elke respondent alle drie soorten broden proeft, dan krijg je te maken met interactie-effecten. Je kunt je dat als volgt voorstellen: stel je hebt een respondent die eerst het ‘ovenheerlijke’ stokbrood proeft, dan het ‘gewone’ witbrood en dan het minder lekkere bruine brood. Deze respondent zal van mening verschillen als de volgorde precies andersom is: eerst het minder lekkere bruine brood, dan het ‘gewone’ witbrood en als laatste het ‘ovenheerlijke’ stokbrood.
De vraag die nu rijst is welke vorm en richting de interactie-effecten hebben. Bijvoorbeeld beïnvloedt X2 de anderen altijd negatief? Of zijn dergelijke veronderstellingen geheel niet voorafgaand aan de meting te maken? Als er geen voorkennis is, dan is het noodzakelijk te veronderstellen dat alle interactie-effecten reëel zijn. De testopzet dient dat te reflecteren door de volgorde waarin de broden geproefd worden telkens te wijzigen. Men krijgt dan per testopzet een segment met bijbehorende steekproeftrekking. Combinatoriek leert dat er n! mogelijke segmenten zijn: voor n=3 zijn dat er dus zes. Zie onderstaande afbeelding.
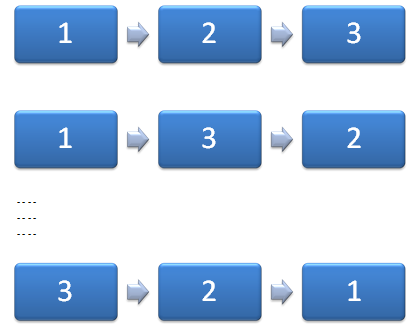
Dat houdt in dat er zes steekproeven getrokken moeten worden. Als dezelfde condities gelden zoals bij de opzet zonder interactie-effect dan geldt ook hier ni=62. Totaal dan 372 verschillende respondenten. Hierbij dient dan wel de voorwaarde gesteld te worden dat de interactie-effecten allemaal onafhankelijk van elkaar zijn, dat is natuurlijk niet helemaal het geval. Het is in dat geval dan ook raadzaam meer respondenten te werven.
Voor de analyse geldt overigens dat de bijbehorende statistiek om de grootte van de interactie-effecten te berekenen is met een full factorial model type III.
Antwoord met Cialdini interactie-effecten
In het geval van de oorspronkelijke vraag met vijf Cialdini-effecten: krijgt elke respondent een Cialdini-effect te zien / te beoordelen? Dan moeten er n! steekproeven getrokken worden en voor n=5 is dat dan 120 steekproeven van elk zeg eens 60 respondenten is dan 7200 respondenten. Dat zou ik niet doen. Ik zou op zoek gaan naar vereenvoudigingen in de onderzoeksopzet,.