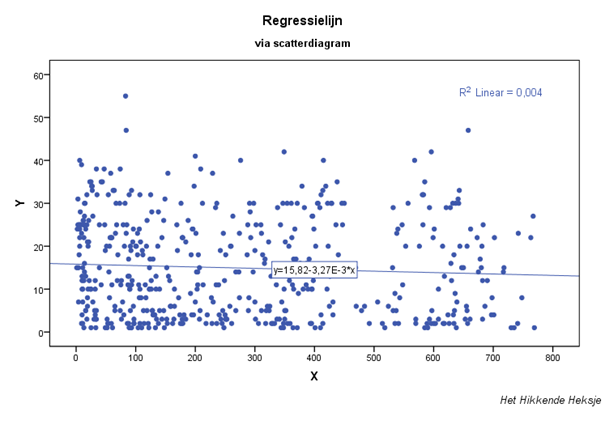
Hoe vlakker de regressielijn, des te minder de
verklarende variabele eraan bijdraagt.
Bij de lijn Y = aX + b is ”a” de richtingscoëfficiënt.
Als a dicht bij nul ligt is de lijn vlak. Oftewel de invloed van de variabele X is heel gering en draagt niet bij tot de verklaring van Y.
Hier is a = -3,27E-3 = -0,00327 en ligt dicht bij nul.
Via SPSS: menu-optie Graphs / Legacy dialogs / Scatter/Dot / Simple Scatter maak je een puntenwolk (= scatter diagram).
Via dubbelklik in je outputscherm bewerk je je grafiek. Klik in de Chart Editor aan de menu-optie Elements / Fit line at total dan krijg je bovenstaande grafiek
Bedenk dat spreiding het centrale begrip in de statistiek is: alles draait om spreiding. Hoe het gespreid is, hoe de waarnemingen (of getallen, of gegevens) verdeeld zijn rondom een midden.
Ik heb een vraag over mijn scriptie. Ik heb de steekproefgrootte voor mijn scriptie berekend en hieruit kwam dat ik 384 respondenten nodig had voor een betrouwbaarheid van 95% en een proportie van 0.5. Uiteindelijk bestaat mijn bruikbare respons uit 190 mensen. Hoe kan ik nu het beste berekeningen doen en significantie aantonen? Bij 190 mensen is de betrouwbaarheid 83,24%. Moet ik dit betrouwbaarheidsinterval dan verder hanteren? En moet ik om significantie aan te tonen een p-waarde <0,05 hebben? Of dan van p < 0,1776? Bij <0,05 klopt het bijbehorende betrouwbaarheidsinterval niet, maar bij p<0,1776 lijken de uitkomsten me heel onbetrouwbaar. Of is het voldoende als ik in de methodologie bij de discussie opneem dat berekeningen zijn gedaan met een 95% betrouwbaarheidsinterval, maar dat het daadwerkelijke interval en daarmee de betrouwbaarheid lager is, namelijk 83,24%?
Antwoord
Mijn antwoord is tweeledig.
Als je een lagere betrouwbaarheid moet hanteren betekent dat dat je onderzoek grotere bandbreedtes kent voor de generalisatie naar de volledige populatie toe. Dus als je een gemiddelde tevredenheid hebt van 7,0 in je steekproef, dan zal het populatiegemiddelde liggen in een 83,24% betrouwbaarheidsinterval eromheen. DUS NIET EEN 95%-betrouwbaarheidsinterval. hetzelfde geldt voor een proportie.
Stel je doet een analyse (zeg eens wat: een chikwadraattoets) en er komt uit dat de toets uitwijst dat met 95% betrouwbaarheid kan zeggen dat er een samenhang is. Wat houdt dat in voor de populatie? Geen idee. Daar heb je te weinig waarnemingen voor. Want: stel je zou er wel voldoende verzamelen, dan kan het muntje alle kanten opvallen: het kan leiden tot een ‘stevig’ significant verschil, maar ook juist naar een ‘stevig’ niet-significant verschil. Dat is het nadeel van te weinig respondenten immers. Je kunt niet met ‘vertrouwen’ extrapoleren naar de populatie toe. Voorzichtigheid is gewenst t.a.v. het trekken van conclusies!