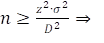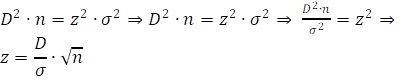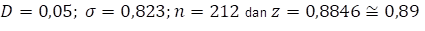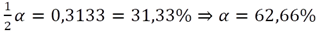Nu ik respons heb, zie ik dat ik de beoogde 384 respondenten
niet heb gehaald. Dat betekent dat ik met minder betrouwbare resultaten
genoegen moet nemen. Hoe bereken ik dat?
Antwoord
De steekproefformule voor een metrische variabele herschrijven
we dan zodanig dat de betrouwbaarheid ‘eruit’ rolt. Zie onderstaande afleiding
(zie p.211).
Om de z-waarde af te leiden, wordt het
ongelijkteken een gelijkteken:
Vul de gegevens van de populatie en de steekproef in en
voilà je krijgt de z-waarde. Van die z-waarde kun je dan in bijlage III (p.256)
de bijbehorende betrouwbaarheid vinden. Stel dat deze gegevens beschikbaar
zijn:
In bijlage III vind je dan in de tabel:
Dit is een maximumwaarde. Dus in plaats van 95% betrouwbaarheid, heb je maar 63% betrouwbaarheid. Bedenk dat het opgooien van een geldstuk 50% kans geeft op ‘kop’. Zoveel meer zekerheid biedt dit onderzoek dus niet. Wil je meer zekerheid dat je resultaten te veralgemeniseren zijn naar de populatie toe (extrapolatie), dan moet je je steekproef vergroten.
Student vroeg mij laatst: mag ik een Likertschaal ook als
metrische variabele hanteren?
Antwoord
Hij wist vast niet dat achter die vraag al heel veel
literatuur schuilgaat. De essentie is:
Ja, als je van plan bent een latente variabele te meten. Dus een nieuwe variabele gaat maken op basis van een aantal vragen met een Likertschaal, zoals een attitude.
Nee, als je alleen maar wil weten wat het antwoord is op een vraag met een Likertschaal.
Daar horen dan ook verschillende analysetechnieken bij (zie hieronder tabel 2). Onderstaand de uitleg van dit antwoord.
Equidistantie
De Likertschaal is een veelgebruikte manier van het vragen naar attitudes en meningen van respondenten (Likert scale, nd). Likert (1932) heeft deze ooit ontworpen om invulling te geven aan de wens om aspecten van persoonlijkheids- en karaktereigenschappen (‘traits of personality and character’) meetbaar te krijgen. De meest gebruikte vorm is in Nederland een vijfpuntsschaal (Brinkman, 2014), maar ook een zevenpuntsschaal komt voor. Een standaard antwoordschaling kent equidistantie ( Likert, 1932; Schriemer, 2014). Equidistantie is een begrip ontleent uit de geografie en betekent ‘gelijke afstanden’. Dat houdt in dit geval in dat de afstand tussen ‘1’ en ‘2’ even groot is als de afstand tussen ‘2’ en ‘3’, enzovoorts. zie tabel 1.
Een voorbeeld waarbij de onderlinge afstanden niet meer gelijk zijn is bijvoorbeeld: 1 = absoluut onwaarschijnlijk, 2 = beetje onwaarschijnlijk, 3 = misschien waarschijnlijk, 4 = waarschijnlijk, 5 = zeer waarschijnlijk. Deze schalen noemen we ongebalanceerd (Berg, Mehciz, Houtkoop-Steenstra & Holleman, 2002) of asymmetrisch (Joshi, Kale, Chandel & Pal, 2012). Over die Likertschaal & -methode is echt veel over geschreven. Een mooi overzichtsartikel is van de hand van Joshi et al (2015) waar ze ingaan op de verschillen en overeenkomsten tussen vijf- en zevenpuntsschalen en (de hamvraag in deze) of je zo’n vraag met een dergelijke schaal nu wel of niet als metrische variabele mag hanteren.
De hamvraag: ordinaal of intervalgeschaald
Om die vraag te beantwoorden moet de onderzoeker eerst vastleggen
wat hij wil: een latente variabele meetbaar maken of (losse) vragen stellen die
de Likertschaling hebben. Joshi et al (2012) stellen dan ook met klem dat die
beslissing vooraf, bij het maken van de vragenlijst, vastgesteld moet zijn door
de onderzoeker en dus niet achteraf. Want er is een verschil tussen vragen met de
bedoeling een Likertschaal te maken en een Likertschaal-achtige vraag. Boone &
Boone (2012) leggen dat omstandig uit.
“(…) Likert-type items as single questions that
use some aspect of the original Likert response alternatives. While multiple
questions may be used in a research instrument, there is no attempt by the
researcher to combine the responses from the items into a composite scale.”
“A Likert scale, on the other hand, is composed
of a series of four or more Likert-type items that are combined into a single
composite score/variable during the data analysis process.”
Het gevolg van die keuze voor de schaling betekent dat er
verschillen zijn in de statistische analyses die je kunt uitvoeren. In
Schriemer (2017) leg ik uit aan de hand van de tabellen 5.1 (p.132) en 6.1 (p.160)
welke analyses gerechtvaardigd zijn, gegeven de schaling van variabelen. In dit
specifieke geval omtrent de Likertschalen is de volgende indeling te maken
(mede geïnspireerd op de artikelen Boone & Boone (2012) en Joshi et al (2015),
zie tabel 2.
Let op: niet neutraal hanteren hè!
Literatuur
Berg, H. van den, Mehciz, M, Houtkoop-Steenstra, H. & Holleman, B.
(2002). Opinie-meten of opinie-maken? De
rol van stellingvragen in markt- en opinieonderzoek. Amsterdam: Stichting
voor Culturele Studies
Boone, H.N. & Boone, D.A. (2012). Analyzing Likert Data. Journal of Extension.
Volume 50, No 2, Article number 2TOT2. Geraadpleegd op 03-03-2019 via https://www.researchgate.net/profile/Mahdi_Safarpour/post/what_is_a_logistic_regression_analysis/attachment/59d622fb79197b8077981513/AS:304626539139073@1449640034657/download/Likert+Scale+vs+Likert+Item+%28Good+Source%29.pdf
Brinkman, J.H.M. (2014). De
vragenlijst. Een goed meetinstrument voor toepasbaar onderzoek.
Groningen/Houten: Noordhoff Uitgevers bv
Joshi, A., Kale, S., Chandel, S. & Pal, D.K. (2015). Likert Scale:
Explored and Explained. British Journal of
Applied Science & Technology 7(4): 396-403. Geraadpleegd 03-03-2019 via
https://www.researchgate.net/publication/276394797_Likert_Scale_Explored_and_Explained
Likert, R. (1932). A
technique for the measurement of attitudes. Archives
of Psychology, 22(140), pp.1–55.
Likert scale (nd). Likert scale. Geraadpleegd op 12-02-2018 via https://en.wikipedia.org/wiki/Likert_scale
Schriemer, M.G. (2017). Statistiek voor de beroepspraktijk.
Statistiek leren lezen, daarna begrijpen en berekenen met SPSS. Voor hbo en wo.
Tweede herziene druk. Haarlem: SVW
Vraag van student: Ik onderzoek of men in Nederland
betrokkenheid heeft met het merk X. Ik heb via mijn Facebookpagina respons
verzameld en ik zie dat ik nu 51% mannen en 49% vrouwen heb, dat houdt toch in
dat ik representatief onderzoek heb gedaan?
Antwoord
Ja, representatief en nee: niet extrapoleren. In de vraag van de student schuilt onbegrip over twee begrippen: representativiteit en extrapoleerbaarheid van de resultaten. Dat laatste houdt in dat de onderzoeksresultaten niet alleen geldig zijn voor de responspopulatie, maar voor de gehele populatie waar de steekproef uit getrokken is.
Voorbeeld
Ik vertaal dit probleem maar even als volgt.
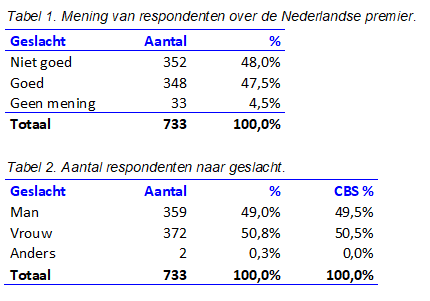
Stel dat ik op het Vrijthof in Maastricht ga staan en ’s middags mensen op het Vrijthof vraag wat zij van de Nederlandse premier vinden. Naast het antwoord (goed / niet goed) noteer ik ook het geslacht van de mensen (man / vrouw / anders). Na vier uur enquêteren heb ik van 733 respondenten respons verzameld; het is een druk plein met het grand café Het Hikkende Heksje in de buurt .
Uit het resultaat blijkt dat de verdeling naar geslacht (man / vrouw) in lijn is met de resultaten van CBS. Dit is met de chikwadraattoets te controleren, dat laat ik nu even aan de lezer over. Zie tabel 1 en 2.
Welke onderzoeksvraag is nu te beantwoorden?
Is de verdeling geslacht man/vrouw representatief met betrekking tot de verhouding in Nederland? Ja
Is dit de mening van ‘de Nederlander’? Nee: dit is de mening van de bezoeker van het Vrijthof.
Mag je dit resultaat extrapoleren naar ‘Nederland’? Nee. Waarom niet? Stel dat ik op de Grote Markt in Groningen gaan staan (ook een druk plein vanwege het grand café Het Hikkende Heksje in Groningen) en hetzelfde onderzoek herhaal en dan 800 mensen enquêteer. Dan is het zeer denkbaar dat al die mensen een heel ander antwoord geven dan de mensen op het Vrijthof. Om te bewijzen dat het de mening van ‘de Nederlander’ is, zal in heel Nederland geënquêteerd moeten worden.
Ik heb een vraag over mijn scriptie. Ik heb de steekproefgrootte voor mijn scriptie berekend en hieruit kwam dat ik 384 respondenten nodig had voor een betrouwbaarheid van 95% en een proportie van 0.5. Uiteindelijk bestaat mijn bruikbare respons uit 190 mensen. Hoe kan ik nu het beste berekeningen doen en significantie aantonen? Bij 190 mensen is de betrouwbaarheid 83,24%. Moet ik dit betrouwbaarheidsinterval dan verder hanteren? En moet ik om significantie aan te tonen een p-waarde <0,05 hebben? Of dan van p < 0,1776? Bij <0,05 klopt het bijbehorende betrouwbaarheidsinterval niet, maar bij p<0,1776 lijken de uitkomsten me heel onbetrouwbaar. Of is het voldoende als ik in de methodologie bij de discussie opneem dat berekeningen zijn gedaan met een 95% betrouwbaarheidsinterval, maar dat het daadwerkelijke interval en daarmee de betrouwbaarheid lager is, namelijk 83,24%?
Antwoord
Mijn antwoord is tweeledig.
Als je een lagere betrouwbaarheid moet hanteren betekent dat dat je onderzoek grotere bandbreedtes kent voor de generalisatie naar de volledige populatie toe. Dus als je een gemiddelde tevredenheid hebt van 7,0 in je steekproef, dan zal het populatiegemiddelde liggen in een 83,24% betrouwbaarheidsinterval eromheen. DUS NIET EEN 95%-betrouwbaarheidsinterval. hetzelfde geldt voor een proportie.
Stel je doet een analyse (zeg eens wat: een chikwadraattoets) en er komt uit dat de toets uitwijst dat met 95% betrouwbaarheid kan zeggen dat er een samenhang is. Wat houdt dat in voor de populatie? Geen idee. Daar heb je te weinig waarnemingen voor. Want: stel je zou er wel voldoende verzamelen, dan kan het muntje alle kanten opvallen: het kan leiden tot een ‘stevig’ significant verschil, maar ook juist naar een ‘stevig’ niet-significant verschil. Dat is het nadeel van te weinig respondenten immers. Je kunt niet met ‘vertrouwen’ extrapoleren naar de populatie toe. Voorzichtigheid is gewenst t.a.v. het trekken van conclusies!
Tijdens college over kansen: ‘als een dobbelsteen zuiver is, dan is de geometrie van de kubus conform de fysische eigenschappen gelijkelijk verdeeld’ repliceert de student ‘hoe zouden we zuiverheid van veelzijdige politici kunnen meten met waarschijnlijkheidsrekening?’