
Vraag
Vraag van student: Ik onderzoek of men in Nederland betrokkenheid heeft met het merk X. Ik heb via mijn Facebookpagina respons verzameld en ik zie dat ik nu 51% mannen en 49% vrouwen heb, dat houdt toch in dat ik representatief onderzoek heb gedaan?
Antwoord
Ja, representatief en nee: niet extrapoleren. In de vraag van de student schuilt onbegrip over twee begrippen: representativiteit en extrapoleerbaarheid van de resultaten. Dat laatste houdt in dat de onderzoeksresultaten niet alleen geldig zijn voor de responspopulatie, maar voor de gehele populatie waar de steekproef uit getrokken is.
Voorbeeld
Ik vertaal dit probleem maar even als volgt.
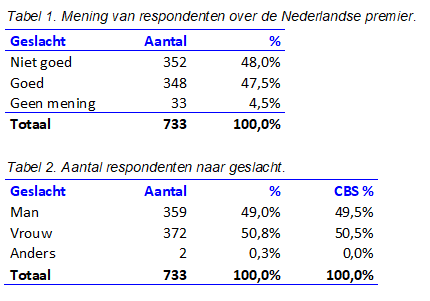
Stel dat ik op het Vrijthof in Maastricht ga staan en ’s middags mensen op het Vrijthof vraag wat zij van de Nederlandse premier vinden. Naast het antwoord (goed / niet goed) noteer ik ook het geslacht van de mensen (man / vrouw / anders). Na vier uur enquêteren heb ik van 733 respondenten respons verzameld; het is een druk plein met het grand café Het Hikkende Heksje in de buurt .

Uit het resultaat blijkt dat de verdeling naar geslacht (man / vrouw) in lijn is met de resultaten van CBS. Dit is met de chikwadraattoets te controleren, dat laat ik nu even aan de lezer over. Zie tabel 1 en 2.
Welke onderzoeksvraag is nu te beantwoorden?
Is de verdeling geslacht man/vrouw representatief met betrekking tot de verhouding in Nederland? Ja
Is dit de mening van ‘de Nederlander’?
Nee: dit is de mening van de bezoeker van het Vrijthof.
Mag je dit resultaat extrapoleren naar ‘Nederland’? Nee. Waarom niet? Stel dat ik op de Grote Markt in Groningen gaan staan (ook een druk plein vanwege het grand café Het Hikkende Heksje in Groningen) en hetzelfde onderzoek herhaal en dan 800 mensen enquêteer. Dan is het zeer denkbaar dat al die mensen een heel ander antwoord geven dan de mensen op het Vrijthof. Om te bewijzen dat het de mening van ‘de Nederlander’ is, zal in heel Nederland geënquêteerd moeten worden.
